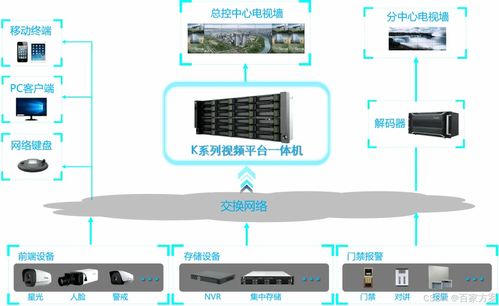
一項基于人工智能技術的“歷史人物復活”黑科技引發熱議。通過深度學習算法與歷史文獻數據,開發者成功為清代雍正、乾隆兩位皇帝生成了高度逼真的數字面容,不僅填補了歷史影像的空白,更讓文學創作中的穿越男主從此“有臉可依”。
這項技術突破源自多模態AI模型的深度應用。開發團隊通過三步實現歷史人物的“數字復活”:從故宮博物院藏《雍正朝服像》《乾隆十駿圖》等宮廷畫作中提取人物面部特征;結合《清實錄》《起居注》中關于帝王容貌的文字描述(如“天庭飽滿”“龍睛鳳頸”),構建三維顱骨模型;利用生成對抗網絡(GAN)技術進行皮膚紋理渲染和動態表情模擬。
值得注意的是,該技術并非簡單“換臉”,而是建立了完整的數字基因庫。系統能根據年齡變化自動調整面容細節——青年乾隆的英氣勃發與晚年乾隆的法令紋深度,都嚴格參照歷史記載進行參數化呈現。開發者甚至通過分析雍正批閱奏折時“每日僅睡兩個時辰”的作息記錄,在數字面容中加入了符合疲勞狀態的眼下青影細節。
文學創作領域對此反響熱烈。多位網絡作家表示,這項技術解決了穿越小說“男主形象模糊”的痛點。以往描寫帝王角色時只能借用影視演員形象,現在可以直接調用AI生成的不同角度參考圖,甚至獲取“登基大典嚴肅表情”“微服私訪輕笑神態”等場景化面容。有作者笑稱:“終于不用再寫‘劍眉星目’這種模板化描寫了。”
技術團隊透露,該模型具備持續進化能力。當輸入新的史料記載時,系統會自動優化面容細節。例如最新發現的傳教士日記中提及乾隆“左眉稍高于右眉”,經數據注入后,數字乾隆的面部對稱度已立即調整。下一步計劃開發語音重建功能,試圖通過朱批奏折的筆跡壓力數據分析,還原帝王說話時的語氣節奏。
不過這項技術也引發史學界討論。有學者提醒,AI重建終究是概率推測,需警惕“數字整容”對歷史認知的影響。對此開發團隊強調,所有生成結果都標注了置信度指數,且專門開發了“史料溯源”功能,可隨時查看支撐每個面部特征的歷史依據。
從雍正乾隆開始,這項技術正在向更廣闊的歷史領域延伸。開發方表示已完成唐代李白、宋代蘇軾的初步建模,未來還將開放個性化定制接口,允許用戶輸入特定描述生成專屬歷史人物形象。當AI讓歷史人物跨越時空與當代人“面對面”,我們或許正在見證數字人文研究的新紀元。